4. A Code Generation Tool for FABRIC
Unlike most RAG code-generation studies noted above, our FABRIC code generation tool is deliberately simple to deploy. Although the quality of input data is always a factor, as will be discussed in a later section, our tool does not require time-consuming manual tagging of input data. Moreover, the whole pipeline can be implemented using small local LLMs and open-source software and libraries.
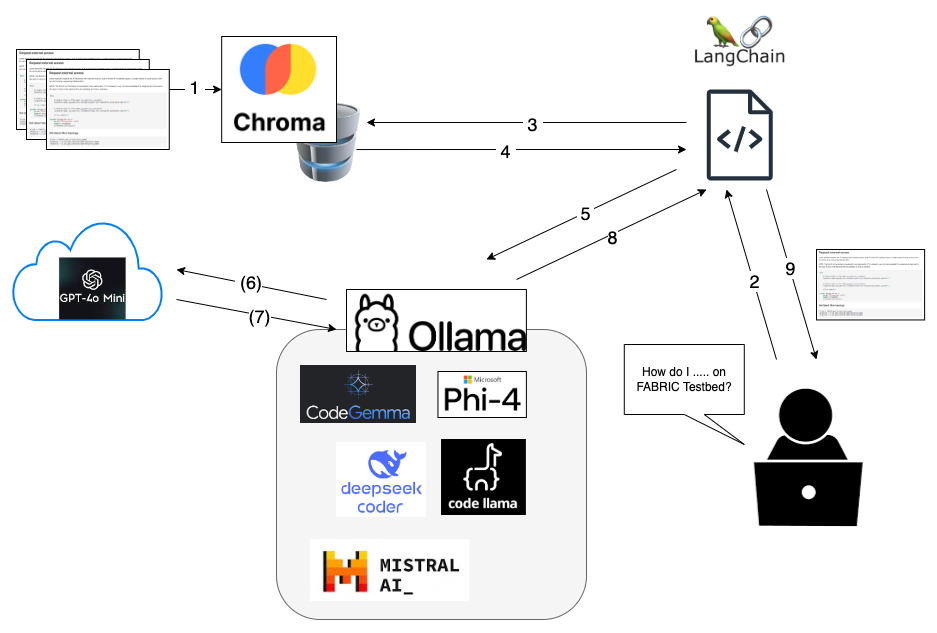
Chroma vector database is created with current Jupyter examples that are used as a reference.
User asks for a notebook to be generated.
User’s query is sent to the vector database.
Small number of documents that are considered relevant to the user’s query are returned.
User’s query along with the retrieved documents are sent to an LLM running through Ollama.
(ONLY IF using GPT-4o-mini) Ollama sends the query along with the retrieved documents to OpenAI using a stored key.
(ONLY IF using GPT-4o-mini) OpenAI sends response back.
LLM’s response (raw) is sent back.
LLM’s response is parsed and returned to the user via GUI.
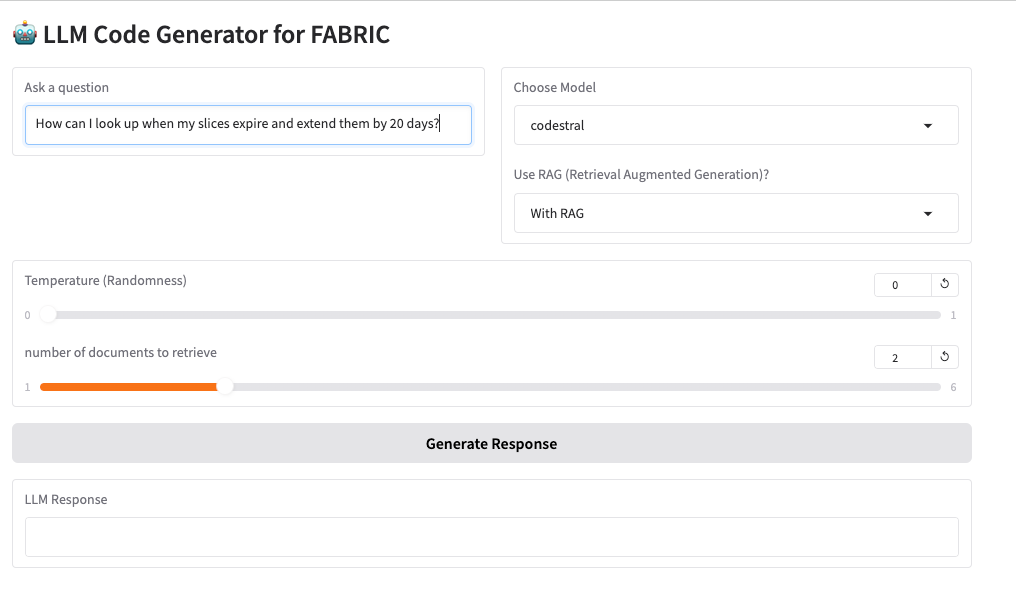
Input (GUI) shows how the user can enter a query, choose LLM, its temperature setting, whether to use RAG, and how many documents to retrieve. The generated code is returned as shown in Output (GUI).