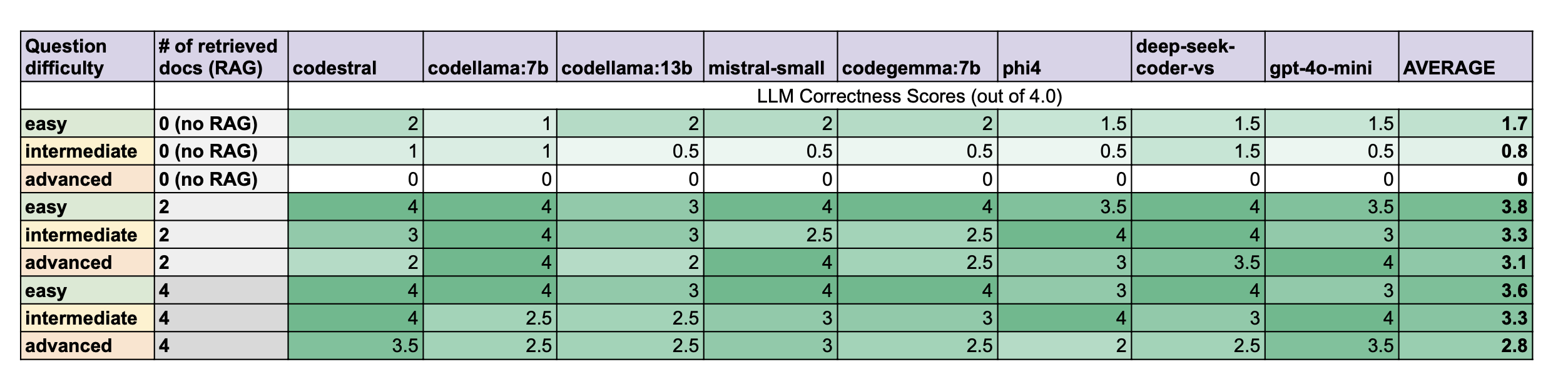
6. Results
To evaluate our RAG model approach, we ingested a (curated) set of FABRIC Notebooks into our Vector Database. We then tested against several of the LLMs mentioned earlier by giving them three distinct queries to answer (i.e., questions to generate FABRIC answers, python scripts, for). We then manually ranked the correctness of the LLM output using a simple scoring system ranging from “Useless” to “Code is correct”.
Queries
We chose three queries for testing, representing three levels of complexities. The queries mimic commonly asked questions by FABRIC users of various levels of expertise.
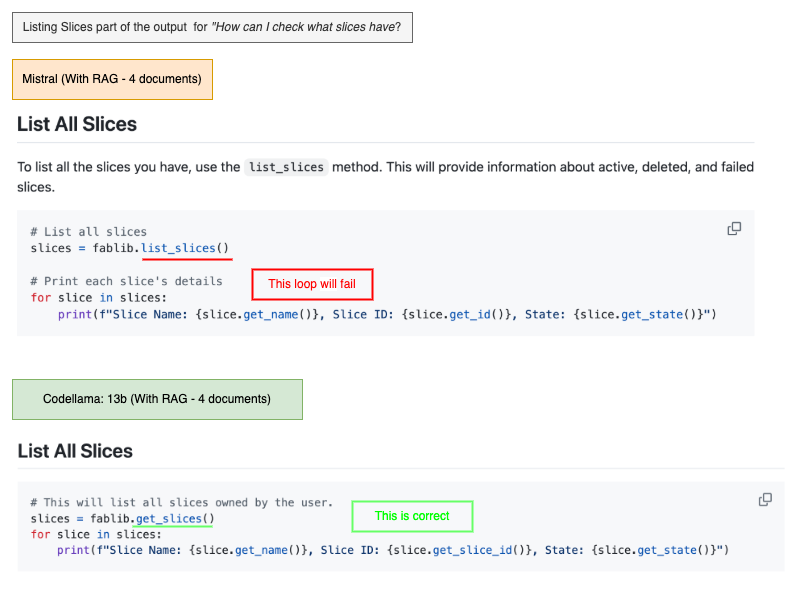
Easy: How can I check what slices I have?
Intermediate: How can I look up when my slices expire and extend them by 20 days?
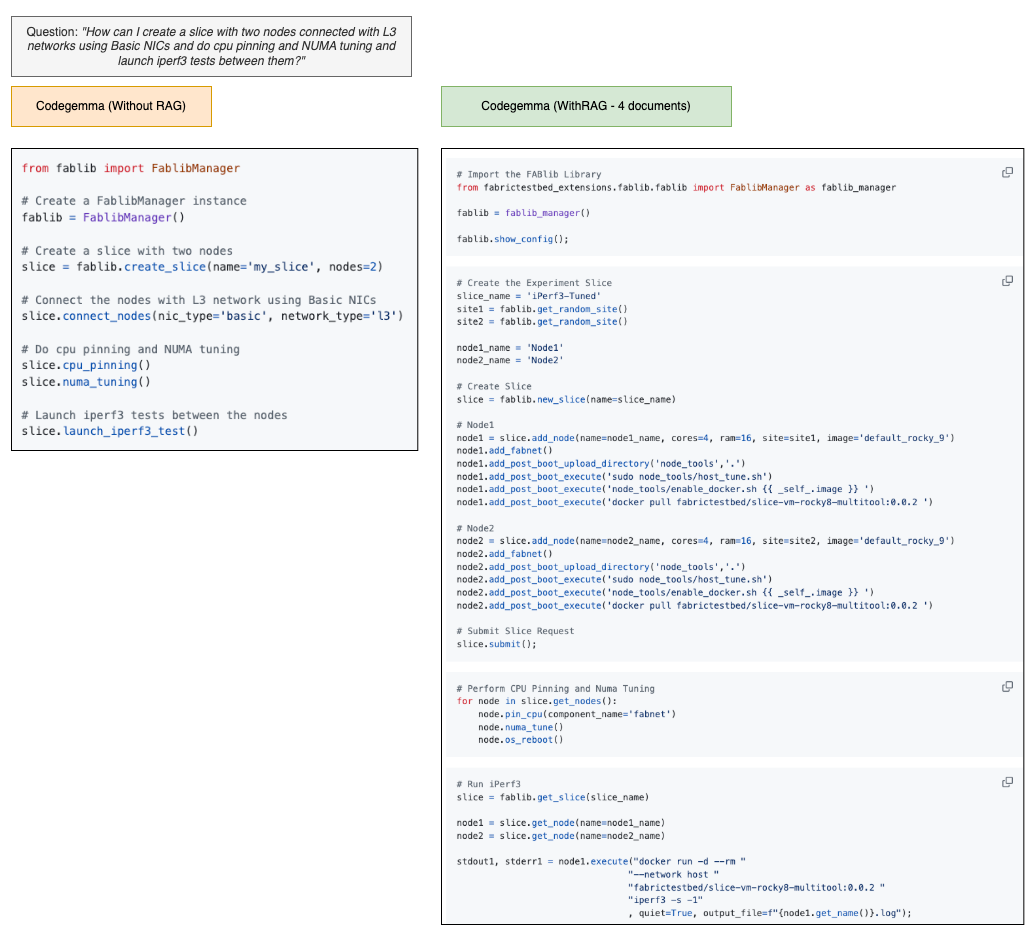
Advanced: How can I create a slice with two nodes connected with L3 networks using Basic NICs and do CPU pinning and NUMA tuning and launch iperf3 tests between them?
Scoring system
We ran each query once for each model, using the temperature of 0.0 as noted above. FABRIC software team members assigned a score of 0~4 described as follows. In many cases, we ran the generated code to confirm that it successfully reserved the correct set of resources:
0: Useless. Largely a result of hallucination.
1: Contain some correct elements but largely incorrect
2: About half correct (some useful sections/elements, but still far)
3: Mostly correct – code would be a good starting point and usable with minor corrections
4: Code is correct and runs without any edits.
Test Results
The effectiveness of using RAG is clearly demonstrated by the results. Without RAG, no model was able to generate error-free code even for the easy query (that could be written in as short as 3 lines of code). For the intermediate-level question, there was little resemblance between the no–RAG generated code and the correct result; and for Question 3 (advanced level), all outputs could be described as hallucinations. Without RAG, therefore, even the highly-rated LLMs are incapable of coherent and useful code for FABRIC users.
On the other hand, if RAG is used (i.e., similar FABRIC code examples retrieved from the vector store are passed to the LLM along with users query), performance improves significantly. For Question #1 (Easy) and #2 (Intermediate), about half the LLMs were able to generate error-free code (see RAG vs. no-RAG (Simple Example)), and even for Question #3 (Advanced), which requires a lengthy and complicated script, the average score using RAG was close to 3, implying that the code is largely correct and can serve as a good starting point even if it contains some minor errors (see RAG vs. no-RAG (Advanced Example)). That is a completely different level of correctness especially when compared to no-RAG LLM correctness for the same question, which was completely useless.
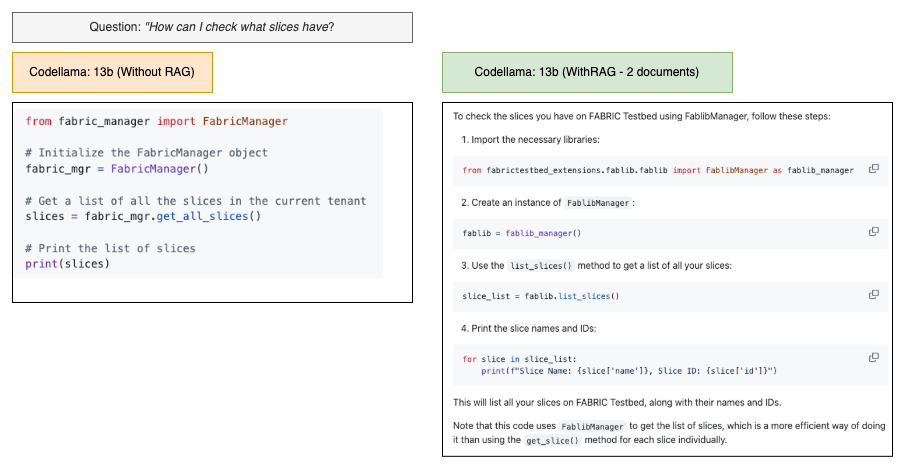
Even with RAG, some details remained imperfect. In Difficult Example (similar methods), list_slices() and get_slices() are similar, but only the output of the latter is iterable. Multiple outputs that used the former included a loop that failed to perform the intended tasks due to this.
Another difficult case is a missing logical step. In Difficult Example (Failing to name a device), failing to name a component means there is no way to refer to it later for running experiments.

Summary of Test Results
Overall, our RAG-based models did surprisingly well at producing correct code. Even in cases where the code was not completely correct, the code could serve as a good starting point for users to write their own code. Non-RAG based approaches (based on standard LLMs) did not produce any usable results.
Our tests show that retrieving 2 documents tends to do slightly better than 4 documents. In some ways, this is a surprising result; it would seem more intuitive if more input data had yielded better results. While it would require more extensive testing to confirm that this holds true for a larger sample set, our analysis of the output suggests that the addition of closely-related, but often unnecessary information in the two extra documents has a tendency to take the focus away from the exact output expected from the query.
Although gpt-4o-mini is said to perform very well especially for its small size and low cost, free pre-trained models available for local set-up performed equally well for our use case. Moreover, increasing the model size does not necessarily correspond to better performance. In fact, the smaller codellama model (7b) performed overall better than its larger model (13b).