Methods
The LROSE group has continued receiving support from the NSF ACCESS Program [Boerner et al., 2023], a program aimed at connecting science researchers and educators to cyberinfrastructure. In September 2024, the LROSE group was granted 730,000 “Service Units” (SUs) for use on the Jetstream2 Cloud (JS2) [Hancock et al., 2021], an allocation which expires in September 2025. The Zero to JupyterHub with Kubernetes project [JupyterHub, n.d.] is a mature project which enables administrators to quickly and easily deploy a JupyterHub server, allowing users to launch single user JupyterLab servers and make use of a powerful ecosystem of tools. This is all accomplished on the back of the jetstream-kubespray project [Zonca, 2023] which facilitates the provisioning of the cyberinfrastructure and the deployment of the Kubernetes (K8s) cluster. The following subsections will discuss: the advantages of containerization, the cluster’s architecture, and the reasoning behind various design choices; methods which have been developed and applied to ensure more efficient use of JS2 resources; and finally, a new development that allows for the use of non-browser based programs and visualization applications accessed via Jupyter.
Containerization and Cluster Architecture
When accessing the LROSE Science Gateway, users are greeted with a containerized
JupyterLab interface running in an environment that has been pre-configured with
the installation of a variety of packages suited to radar and lidar meteorology,
including the LROSE suite of software and packages managed via the conda (or
mamba) package manager. The most significant advantage of this is that gateway
visitors do not need to worry about installing software themselves, a task that
can take valuable time and effort to troubleshoot across a variety of different
operating systems and architectures should something go wrong, effectively
eliminating the “well, it worked on my machine” problem. The Dockerfile and
necessary build files are found on the
lrose-circleci
repo on GitHub.
Gateway users are allocated 10GB of persistent storage space in their home
directories, enough for basic data analysis and visualization. Included in their
home directory is a clone of the lrose-hub repository [DeHart et al., 2024],
which includes a multitude of tutorials focused on common workflows applied
using LROSE tools. The newest commits to this repository are automatically
pulled when a user logs in to their server, ensuring that they have access to
the newest versions of new and existing tutorials. In addition, a large shared
drive is made available to gateway users, so they may explore a larger collection
of data sets for research or teaching purposes.
Kubernetes is a “container orchestration engine” which takes on the responsibility of managing the creation of new containers, the networking between them, and interactions between containers and cloud providers, to name a few [The Kubernetes Authors, 2025]. To deploy Kubernetes on Jetstream2 and benefit from the aforementioned advantages, we use Jetstream-Kubespray, which has two primary components:
Terraform, an Infrastructure as Code technology [Hashicorp, 2025]
Ansible, an automation technology [Red Hat Inc., 2025]
After setting some parameters in a Terraform variable file, most importantly the number of virtual machines (referred to as VMs, or nodes) and their “flavor” (relating to CPU and RAM), Terraform will then interact with JS2 to create the virtual machines, networks, attach IPs, open network ports to traffic, etc. We then run some Ansible “playbooks”, a set of instructions codified in YAML files, which are provided by the Jetstream-Kubespray project to deploy Kubernetes on top of the newly created infrastructure. This process involves applying security updates, downloading and installing all of the software required by Kubernetes, as well as automating some system administrative tasks such as copying over certificates and configuration files.
Aside from the initial deployment, Jetstream-Kubespray can also be used to destroy and “scale” the cluster. In this context, scaling refers to the addition or removal of nodes from the cluster. It is noted, however, that both the initial deployment and the scaling of the cluster can be a time-consuming task, with large scaling procedures of multiple nodes taking an hour or more to run to completion.
Lastly, we use standard Kubernetes workflows to deploy containers and services.
Importantly, the Zero to JupyterHub project provides a helm
chart, the Kubernetes equivalent of a .deb or .rpm package [Helm Authors, 2025], to
install JupyterHub. The configuration for JupyterHub is encoded in a yaml
file, and it is in this file that we can set important parameters such as: the
custom JupyterLab container image and tag, authentication information, the CPU
and RAM allocated per user, additional environment variables, commands to run on
container startup, etc.
This deployment procedure is outlined in Fig. 2.
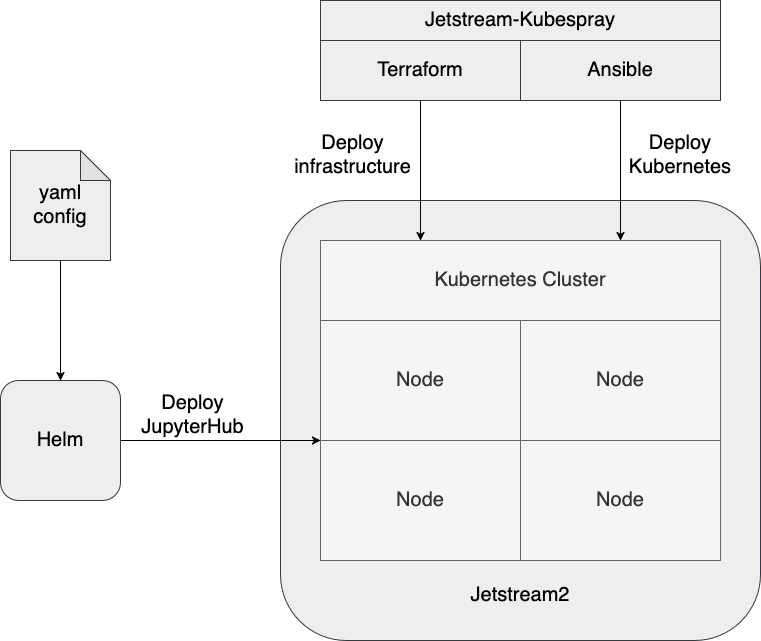
Fig. 2 The different components of Jetstream-Kubespray, using Terraform to provision cloud infrastructure on Jetstream2, Ansible to deploy Kubernetes, and finally Helm to install JupyterHub.
Before allowing access to the gateway, several more tasks must be accomplished:
Configure HTTPS for secure access to the gateway
Configure an authentication provider
Ensure JupyterHub components are scheduled on dedicated nodes
We acquire a free SSL/TLS certificate from the LetsEncrypt certificate authority. This is made simple by Kubernetes, where the process is as easy as applying a handful of Cert-Manager [cert-manager, n.d.] “manifests” (YAML files used by K8s to specify resources to deploy). In addition to obtaining the certificate, cert-manager will also automatically renew the certificates to continually ensure secure connections to the gateway.
We create a GitHub OAuthenticator application to provide authentication to the gateway. We chose GitHub OAuth as it is a reliable, proven technology. In addition, many gateway users already have a GitHub account, and if they do not, it is free to sign up.
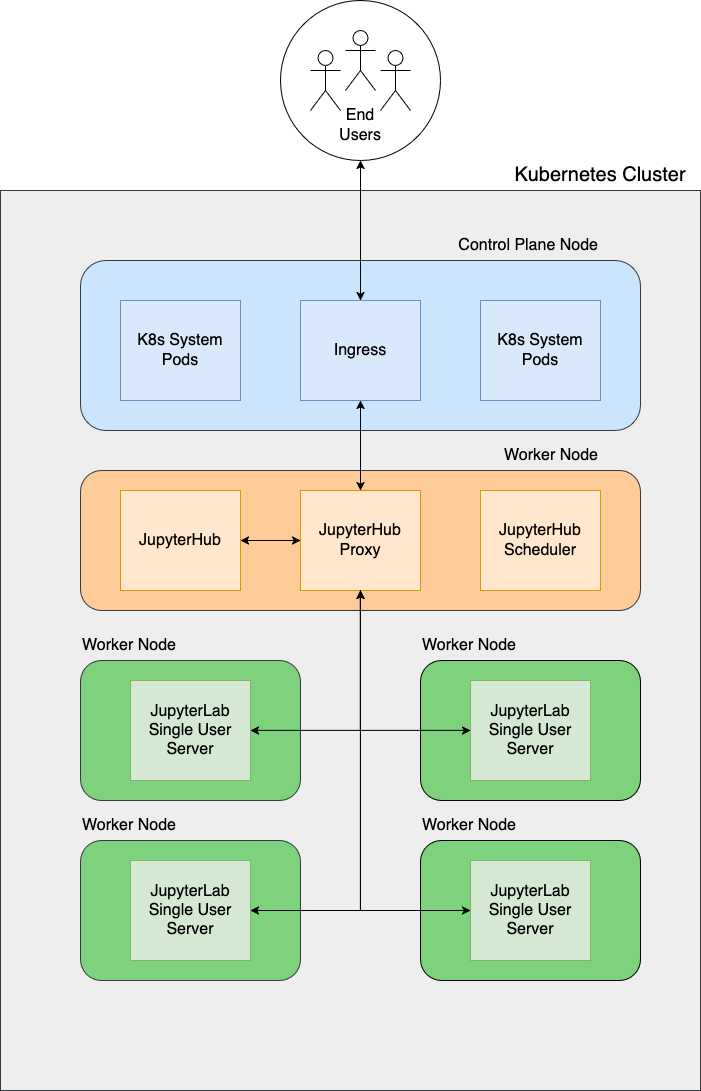
One issue that was encountered previously was with running computationally intensive processes which would attempt to use all the CPU resources allocated to a single user server, as described in [DeHart et al., 2024]. JupyterHub runs a set of “core” Pods which are necessary for the cluster’s functionality. These core Pods include: the JupyterHub server itself which hosts the JupyterHub API and is responsible for authenticating users, administration, and launching single user servers, among other tasks; the user scheduler, which is responsible for determining on which node to launch a new single user server; and the proxy server, which routes incoming traffic between the different JupyterHub components and the end-user.
Without any additional configuration, single user servers will be scheduled on any available node. If single user servers are scheduled on the same node as the JupyterHub “core” Pods and computationally intensive processes are run, the single user servers may exhaust all the node’s resources, preventing the JupyterHub core Pods from performing their necessary functions, subsequently crashing the JupyterHub.
To remedy this, we dedicate a new “core” node to these core Pods via the following:
Apply a Kubernetes “Taint” to the core node, preventing single user servers from spawning on this node
Apply a Kubernetes “Label” to the core node
Configure core Pods to use the above label as a “nodeSelector”, requiring them to be scheduled on the core node
Configure core Pods with the appropriate “Toleration” for the Taint described in step 1)
The final architecture for the Kubernetes cluster and JupyterHub on top of that is shown in Fig. 3.
Allocation Management
As previously discussed, allocations on Jetstream2 exchange Service Units (SUs) for CPU core hours. In the previous section, it was explained how Kubespray was used to deploy clusters, and how Kubernetes administrative procedures were used to dedicate a node to core JupyterHub components. In addition, a standing set of nodes are made available to accommodate a certain number of gateway visitors. However, when the gateway is not receiving heavy traffic, these nodes are unused, and idling away SUs. This can be problematic, especially for Jetstream2 users with smaller allocations.
We developed a script to help monitor our SU usage and better make informed
decisions over the number of nodes we can realistically have idling without
going “over budget”. This
script
will query Jetstream2’s openstack interface for a token which can then be used
to request allocation information via an API [JetstreamCloud, n.d.]. Current
SU usage and our total allocated SUs are included as part of the retrieved
information, which is then stored in a .csv file. This data is then used to
construct a basic linear model and forecast an SU surplus or deficit at the end
date of our allocation. This “SU delta” can be used to predict how many
additional nodes we can potentially add to the cluster, or how many must be
removed from the cluster in order to stay within the SU bounds of our
allocation.
As an alternative to the time-consuming scaling procedure mentioned in the previous section, which fully destroys and removes nodes from the cluster, we apply the method of “soft-scaling” first described in [Zonca, 2024] and previously reported as being used by our team in [DeHart et al., 2024]. To summarize, a “soft-down-scale” will first remove all Pods from a selection of nodes, tell Kubernetes to prevent new Pods from being scheduled on them, and finally put the nodes in a “shelved” state, a VM state which will not consume SUs. A “soft-up-scale” will perform the same procedure in reverse. Both the down and up-scaling procedures can scale the cluster in a matter of minutes, a massive improvement from the traditional method of scaling solely via Kubespray.
This method, however, still requires manual intervention by a software engineer. Furthermore, if the cluster has been soft-scaled down and the gateway receives an unexpectedly large number of visitors, the user will be greeted with an “insufficient resources” error upon login. Recent advancements by the Jetstream2 team to bring Openstack Magnum [The OpenInfra Foundation, 2025] to their cloud will address this problem. Magnum is the Openstack project’s version of “Kubernetes as a Service” (KaaS). The “X as a Service” (XaaS) terminology is common to describe different capabilities of cloud service providers where the implementation details of the service are abstracted away from cloud consumers who are instead presented with an API, tool, or web dashboard in order to access the cloud functionality. As of the time of this paper’s writing, Openstack self-describes as providing “infrastructure-as-a-service” functionality.
In a similar fashion to how Jetstream2 users can easily request virtual machines, virtual networking infrastructure, and persistent storage, they can now request entire Kubernetes clusters with a small handful of commands [Zonca, 2024]. Provisioning the necessary cyberinfrastructure and deploying Kubernetes “by hand” as is the case with Kubespray is no longer necessary, as this is abstracted away by Magnum KaaS. K8s clusters deployed via Magnum, which we refer to as Magnum clusters for simplicity, can be provisioned in a time as short as 10 minutes, a massive improvement when compared to Kubespray.
NOTE: While the authors of this paper do not have a direct hand in managing Magnum on Jetstream2, we have been made aware through conversations with Jetstream2 administrators that this improvement is made possible by preconfiguring several virtual machine images (one for each available K8s version), which are then used to create VMs which are readily added to a new or existing K8s cluster. On the backend (i.e. the JS2 side), these clusters are ultimately managed by StackHPC’s ClusterAPI. As this is second hand information, we urge the curious reader to reach out to the Jetstream2 team for further and more accurate implementation details.
In addition, Magnum clusters also have the option to enable cluster auto-scaling. With auto-scaling, gateway administrators can configure the cluster with some minimum number of nodes to ensure quick gateway access. If the gateway receives a sudden large influx of users, the Magnum cluster will intelligently determine how many nodes to add to the cluster to ensure all visitors have resources. When users log out, the node will be destroyed and removed from the cluster, ensuring that resources do not idle away SUs. While cluster auto-scaling on its own does not have fail-safes to ensure we do not go “over-budget” on our allocation, the increased SU usage efficiency in conjunction with our established SU monitoring method allows us to stretch our allocated SUs further and ultimately provide gateway access to more users.
The total amount of time from login to JupyterLab interface for a user who has triggered the auto-scaler is about five minutes and does not require intervention by a software engineer past the initial configuration. The scale down process is observed to trigger 10 minutes after all users have evacuated a node.
Auto-scaling clusters provide us with opportunities to configure our gateway in
ways that may have not been feasible before. One example of this makes use of
Magnum’s concept of “NodeGroups”. Nodegroups allow for the easy deployment of
heterogeneous clusters, i.e. clusters composed of more than 1 flavor of node. By
creating a nodegroup of m3.quad nodes (4 vCPUs, 15GB RAM), and another of
m3.medium nodes (8 vCPUs, 32 GB RAM), we can give gateway users the option to
select between a “low power” and “high power” compute profile. This on-demand
selection of compute power allows for a greater diversity of gateway users,
ranging from the absolute beginner who is learning the ropes, to the faculty
researcher who is analysing large data sets. Other opportunities are being
explored, one of which is described in the following section.
Virtual Desktop
Many data visualization applications were written in a non-cloud-native fashion and were intended to be used within a desktop environment. These quick and powerful applications may be parts of established workflows that should not be ignored by gateway developers. While virtual desktop technology, such as VNC, is nothing new, some questions remained on how to incorporate them into a JupyterHub-based science gateway. As virtual desktop functionality was desired by both the NSF Unidata Program Center and the LROSE project, NSF Unidata developers worked to bring this technology to both project’s gateways.
The team built upon NSF Unidata’s CloudStream project [Fisher and Oxelson Ganter, 2016] and adapted the techniques laid out there to a JupyterLab environment. This new jupyter-with-vnc project [Espinoza, 2025] makes use of several key technologies:
Xvfb (X Virtual Frame Buffer): a virtual X server for use when there is not a physical display attached to a system [Wiggins and Inc, 2025]
XFCE4: a minimalistic Linux desktop environment [XFce Development Team, 2025]
x11vnc: a VNC (Virtual Network Computing) virtual desktop server [Runge, 2010]
noVNC: a VNC client [Martin et al., 2025]
jupyter-server-proxy: a proxy server for JupyterLab, allowing one to access services running alongside JupyterLab using the JupyterLab URL [Project Jupyter Contributors, 2025]
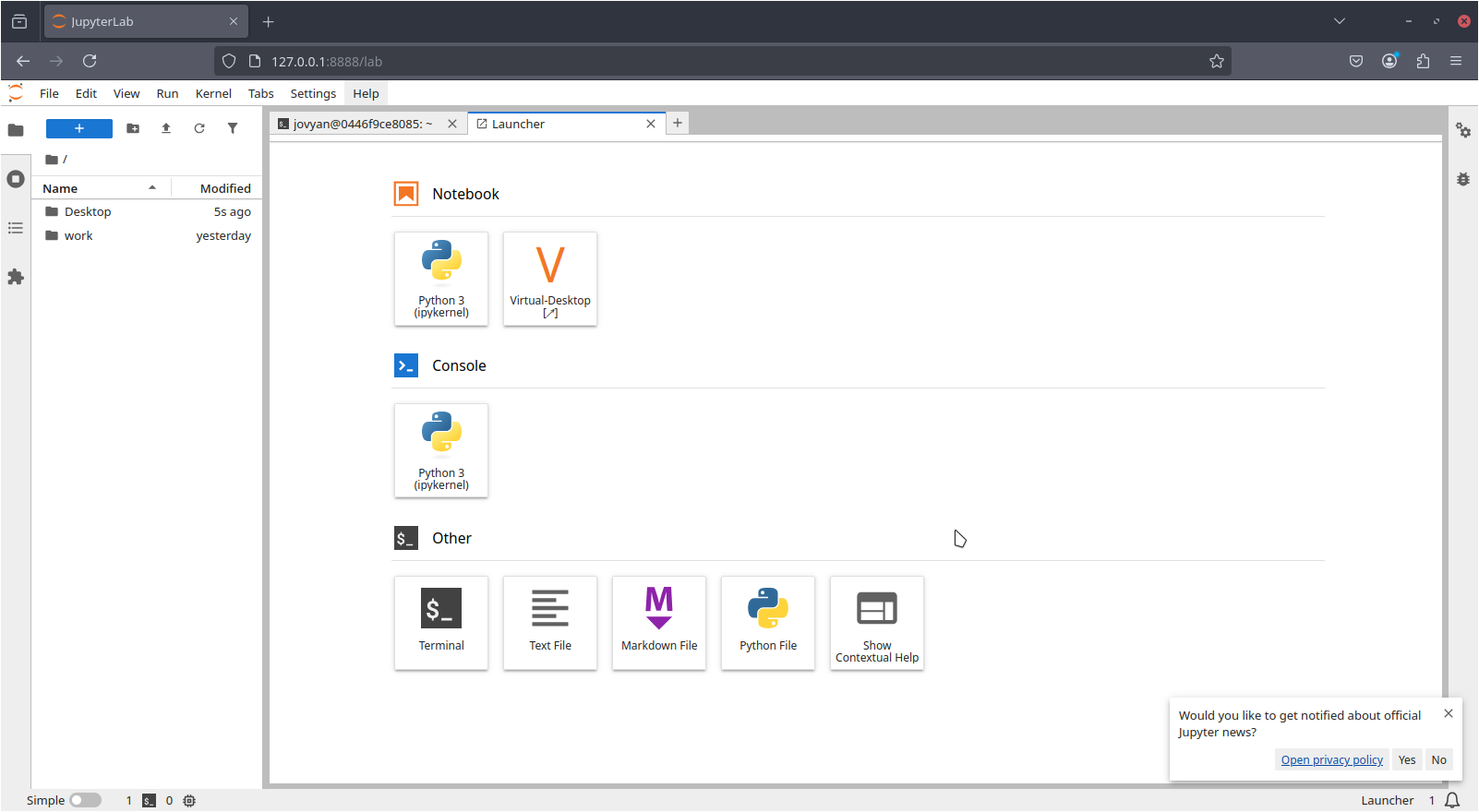
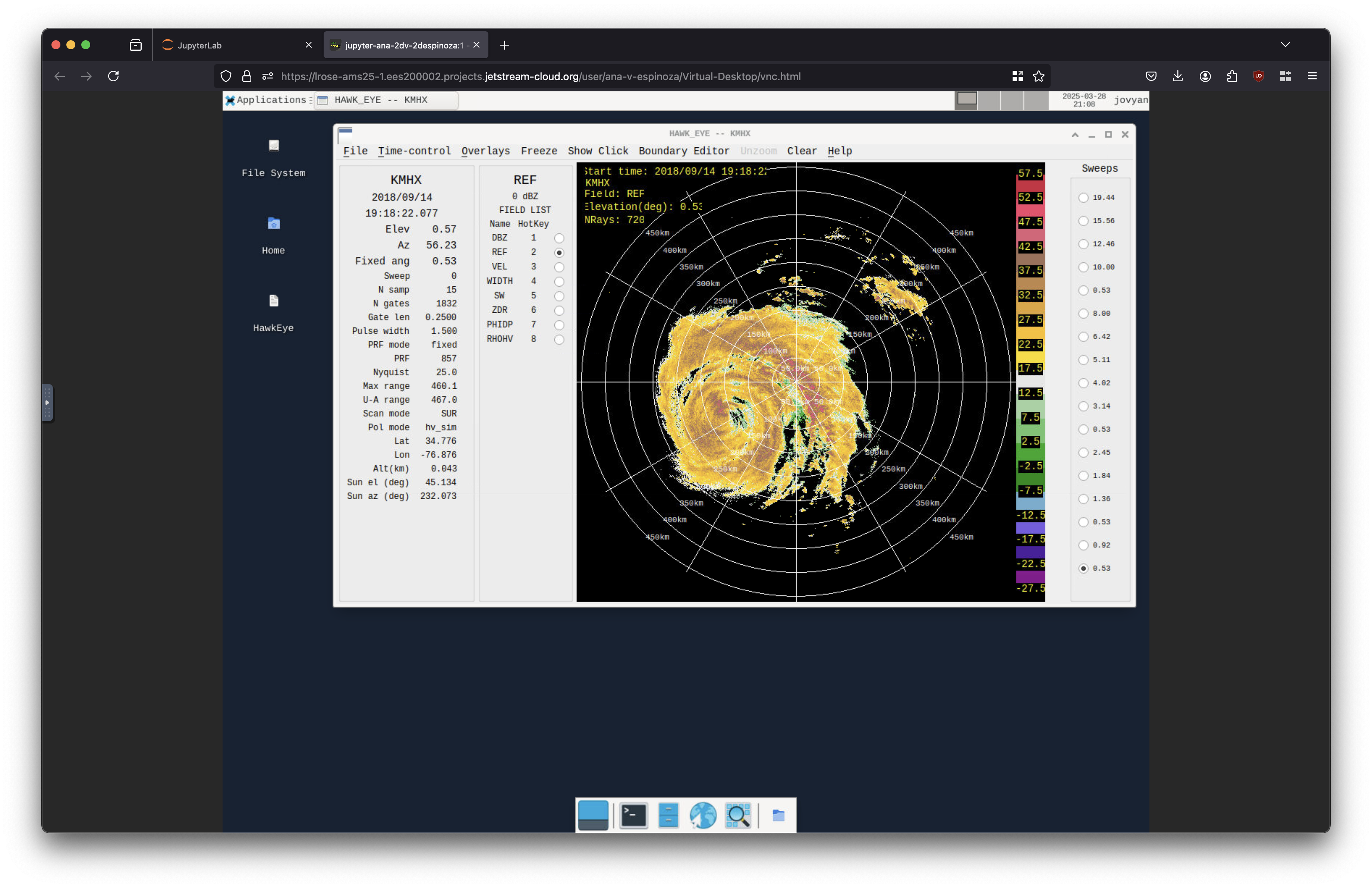
Each of these technologies were installed and configured in the same JupyterLab image running in the gateway. The virtual X server provides the XFCE4 desktop environment a display on which to draw windows, such as those of data visualization software. The x11vnc server will allow the user to connect to the desktop via the noVNC client. Finally, the jupyter-server-proxy allows users to access the noVNC client from behind the authentication and security mechanisms set in place by JupyterHub, as well as adding a convenient “Virtual-Desktop” Launcher card. Science gateway users are now able to use established visualization software such as LROSE’s HawkEye, and NSF Unidata’s Integrated Data Viewer. Example images are shown in Fig. 4 and Fig. 5.