![]()
Cloud microphysics training and aerosol inference with the Fiats deep learning library
Authors: Damian Rouson, Zhe Bai, Dan Bonachea, Baboucarr Dibba, Ethan Gutmann, Katherine Rasmussen, David Torres, Jordan Welsman, Yunhao Zhang
Keywords: deep learning, Fortran, cloud microphysics, aerosols, surrogate model, neural network
Abstract
This notebook presents two atmospheric sciences demonstration applications in the Fiats deep learning software repository. The first, train-cloud-microphysics, trains a neural-network cloud microphysics surrogate model that has been integrated into the Berkeley Lab fork of the Intermediate Complexity Atmospheric Research (ICAR) model. The second, infer-aerosol, performs parallel inference with an aerosol dynamics surrogate pretrained in PyTorch using data from the Energy Exascale Earth System Model (E3SM). This notebook presents the program statements involved in using Fiats for aerosol inference and microphysics training. In order to also give the interested reader direct experience with using Fiats for these purposes, the notebook details how to run two simpler example programs that serve as representative proxies for the demonstration applications. Both proxies are also example programs in the Fiats repository. The microphysics training proxy is a self-contained example requiring no input files. The aerosol inference proxy uses a pretrained aerosol model stored in the Fiats JavaScript Object Notation (JSON) file format and hyperlinked into this notebook for downloading, importing, and using to perform batch inference calculations with Fiats.
Introduction
Background
Fortran programs serve an important role in earth systems modeling from weather and climate prediction [Mozdzynski et al., 2015, Skamarock et al., 2008] to wildland fire modeling [Vanella et al., 2021] and terrestrial ecosystem simulation [Shi et al., 2024]. The cost of performing ensembles of runs of such complex, multiphysics applications at scale inspires investigations into replacing model components with neural-network surrogates in such earth systems as groundwater [Asher et al., 2015] and oceans [Partee et al., 2022]. For the surrogates to be useful, they must provide comparable or better accuracy and execution speed as the physics-based components that the surrogates replace. The prospects for achieving faster execution depend on several properties of the surrogates, including their size, complexity, architecture, and implementation details. Implementing the surrogates in the language of the supported application reduces interface complexity and increases runtime efficiency by reducing the need for wrapper procedures and data structure transformations. Inspired partly by these concerns, native Fortran software packages are emerging to support the training and deployment of neural-network surrogate models. Two examples are neural-fortran [Curcic, 2019] and ATHENA [Taylor, 2024]. This Jupyter notebook presents two demonstration applications in the repository of third example: the Fiats deep learning library [Rouson et al., 2025], [Labb]. One application trains a cloud microphysics surrogate for the Intermediate Complexity Atmospheric Research (ICAR) model [Gutmann et al., 2016]. The other application uses a pretrained surrogate for aerosols in the Energy Exascale Earth Systems Model (E3SM) [Golaz et al., 2019].
Fiats, an acronym that expands to “Functional inference and training for surrogates” or “Fortran inference and training for science,” targets high-performance computing applications (HPC) in Fortran 2023. Fiats provides novel support for functional programming styles by providing inference and training procedures that have the pure attribute. The Fortran standard requires that procedures invoked inside Fortran’s do concurrent loop-parallel construct must be pure. At least four compilers are currently capable of automatically parallelizing do concurrent on central processing units (CPUs) or graphics processing units (GPUs): the Intel Fortran Compiler ifx, LLVM flang, the NVIDIA HPC Fortran compiler nvfortran, and the HPE Cray Compiling Environment Fortran compiler crayftn. Providing pure inference and training procedures thus supports parallel programming across compilers and hardware.
When compiled with flang, for example, Fiats offers automatic parallelization of batch inference calculations with strong scaling trends comparable to those achievable with OpenMP directives [Rouson et al., 2025]. These results were obtained by building LLVM flang from source using the paw-atm24-fiats git tag on the Berkeley Lab LLVM fork. The relevant features were merged into the llvm-project main branch in April 2025 and will be part of the LLVM 21 release. Work is also under way to support ifx.
Fiats provides a derived type that encapsulates neural-network parameters and provides generic bindings infer and train for invoking inference functions and training subroutines, respectively, of various precisions. A novel feature of the Fiats design is that all procedures involved in inference and training have the non_overridable attribute, which eliminates the need for dynamic dispatch at call sites. In addition to simplifying the structure of the resulting executable program and potentially improving performance, we expect this feature to enable the automatic offload of inference and training to GPUs.
What most distinguishes Fiats from similar projects is the Fiats project’s dual purposes as a platform for deep learning research and for exploring how novel programming patterns in Fortran an 2023 can benefit deep learning. Our close collaboration with compiler developers leads to innovations such as the aforementioned use of the non_overridable attribute, which we did not find anywhere in the other aforementioned Fortran deep learning libraries. Non_overridable is the linchpin in efficiently combining functional, object-oriented, and parallel programming, i.e., combining pure, class, and do concurrent, respectively. To see the connection, consider that Fortran requires the passed-object dummy argument (the object on which a type-bound procedure is invoked) to be declared with the keyword class, which nominally connotes polymorphism. Using class allows the dynamic type of the object to vary from one invocation to the next. Polymorphism, one of the central pillars of object-oriented programming, drives the need for dynamic dispatch: compilers must create executable programs that can make a runtime decision about whether to invoke the version of a procedure defined by the type named in the declaration or to invoke a version of the procedure provided by a child type that overrides the procedure. Eliminating the need for this decision avoids unnecessary overhead on CPUs and is essential on GPUs. Neither LLVM flang nor its C++ counterpart, clang++, supports dynamic dispatch on GPUs.
Objectives
The primary objectives of this notebook are to describe the use of Fiats in the infer-aerosol and train-cloud-microphysics demonstration applications and to provide the user experience with Fiats by detailing how to run simpler example programs that use Fiats in similar ways to the demonstration applications and thus serve as reasonable proxies for the demonstration applications. The aerosol inference proxy performs batch inference calculations using a pretrained aerosol model [Bai et al., 2024] provided via hyperlink in this notebook. The cloud microphysics proxy trains a deep neural network to model an ICAR SB04 cloud microphysics model function that predicts the saturated mixing ratio from a given pressure and temperature. The Methodology section of this notebook describes the use of Fiats in the two demonstration applications. The Discussion section explains how to run the two proxies. We expect that the reader familiar with recent Fortran standards will learn the program statements required to use Fiats. We further expect that an interested reader who installs the prerequisite build system and compiler will learn to run programs locally using Fiats.
Methods
Getting started
With the tree utility installed, the following bash shell commands will download the Fiats repository, checkout the git commit used in writing this notebook, and show the Fiats directory tree:
git clone --branch sea-iss-2025 git@github.com:berkeleylab/fiats
cd fiats
tree -d
.
├── demo
│ ├── app
│ ├── include -> ../include
│ ├── src
│ └── test
├── doc
│ └── uml
├── example
│ └── supporting-modules
├── include
├── scripts
├── src
│ └── fiats
└── test
where the src directory contains the source comprising the Fiats library that programs link against to access the Fiats library’s data entities and procedures. As such, src contains the only files that a Fiats user needs, and it contains no main programs. The fiats_m modulein src/fiats_m.f90 exposes all user-facing Fiats functions, subroutines, derived types, and constants. The src/fiats subdirectory contains the definitions of everything in fiats_m as well as private internal implementation details. For a program to access Fiats entities, it would suffice for a use fiats_m statement to appear in any program unit or subprogram that requires Fiats.
Apart from the library, the Fiats git repository contains main programs that demonstrate how to use Fiats. The main programs are in two subdirectories:
example/contains relatively short and mostly self-contained programs anddemo/app/contains demonstration applications developed with collaborators for production use. The next two subsections describe the demonstration applications. Using the demonstration applications requires several problem-specific files and prerequisite software packages. Usingtrain-cloud-microphysicsalso requires considerable resources in the form of thousands of core-hours of ICAR runs to produce hundreds of gigabytes of data. To give the reader a gentler introduction to using Fiats, the Discussion section describes how to use the example programs only.
Demonstration application: aerosol inference
The demo/app/infer-aerosol.f90 program demonstrates the use of Fiats to predict aerosol variables for E3SM. The following statement provides access to all Fiats entities employed by the program:
use fiats_m, only : unmapped_network_t, tensor_t, double_precision, double_precision_file_t
where the unmapped_network_t derived type encapsulates a neural network that performs no mappings on input and output tensors, tensor_t encapsulates network input and output tensors, double_precision is a kind type parameter that specifies the desired precision, and the double_precision_file_t derived type provides a file abstraction that determines how numerical values in model files will be interpreted. Because Fiats focuses on surrogate models that must be compact in order to be competitive with the physics-based models they replace, Fiats uses a JSON file format for its human readability because we have found the ability to inspect network parameters visually helpful in the early stages of experimenting with new algorithms. Users with models trained in PyTorch can use the Fiats companion network export software Nexport to export models to the Fiats JSON format.
After chores such as printing usage information if a user omits a required command-line argument, the following object declaration demonstrates the first direct use of Fiats in the program:
type(unmapped_network_t(double_precision)) neural_network
Fiats uses derived type parameters – specifically kind type parameters – so that one neural-network type can be used to declare objects with any supported kind parameter. Currently, the supported kind parameters are default_real and double_precision, corresponding to the chosen compiler’s real (with no specified kind parameter) and double precision types. Fiats types with a kind type parameter provide a default initialization of the parameter to default_real.
A later line defines the object:
neural_network = unmapped_network_t(double_precision_file_t(path // network_file_name))
where unmapped_network_t appears in this context as a generic interface patterned after Fortran’s structure constructors that define new objects. Because the JSON specification does not differentiate types of numbers (e.g., JSON does not distinguish integers from real numbers), using the Fiats double_precision_file_t type specifies how to interpret values read from the model file.
Similarly, the later line:
type(tensor_t(double_precision)), allocatable :: inputs(:), outputs(:)
specifies the precision used for tensor objects, and the tensor_t generic interface in the following statement:
inputs(i) = tensor_t(input_components(i,:))
resolves to an invocation of a function that produces a double-precision object because of a declaration earlier in the code (not shown here) that declares input_components to be of type double precision. Ultimately, inference happens by invoking a type-bound infer procedure on the neural_network object and providing tensor_t input objects to produce the corresponding tensor_t output objects:
!$omp parallel do shared(inputs,outputs,icc)
do i = 1,icc
outputs(i) = neural_network%infer(inputs(i))
end do
!$omp end parallel do
where we parallelize the loop using OpenMP directives. Alternatively, the Fiats example/concurrent-inferences.F90 program invokes infer inside a do concurrent construct, taking advantage of infer being pure. This approach has the advantage that compilers can automatically parallelize the iterations without OpenMP directives. Besides simplifying the code, switching to do concurrent means the exact same source code can run in parallel on a CPU or a GPU without change. With most compilers, switching from running on one device to another requires simply recompiling with different flags. See Rouson et al. [2025] for more details on automatically parallelizing inference, including strong scaling results on one node of the Perlmutter supercomputer at the National Energy Research Scientific Computing (NERSC) Center.
The remainder of infer-aerosol contains problem-specific statements not directly related to the use of Fiats and is therefore beyond the scope of this notebook.
Demonstration application: microphysics training
Training a neural network is an inherently more involved process than using a neural network for inference. As such, train-cloud-microphysics uses a larger number of Fiats entities:
use fiats_m, only : tensor_t, trainable_network_t, input_output_pair_t, mini_batch_t, &
tensor_map_t, training_configuration_t, training_data_files_t, shuffle
where only the tensor_t type intersects with the set of entities that infer-aerosols uses. The remaining entities in the above use statement all relate to training neural networks.
The trainable_network_t type extends the neural_network_t type and thus offers the same type-bound procedures by inheritance.
Outwardly, trainable_network_t differs from neural_network_t only in that trainable_network_t provides public train and map_to_training_ranges generic bindings that neural_network_t lacks. Calling train performs a forward pass followed by a back-propagation pass that adjusts the neural-network weights and biases. If the network input and output ranges for training differ from the corresponding tensor values for the application (e.g., we often find it useful to map input tensor values to the unit interval [0,1] for training), then calling map_to_training_ranges performs the desired transformation and the resulting tensor_map_t type encapsulates the forward and inverse mappings. Privately, the trainable_network_t type stores a workspace_t object containing a training scratchpad that gets dynamically sized in a way that is invisible to Fiats users. Hiding this implementation detail without forcing the neural_network_t type to have components needed only for training is the primary reason that trainable_network_t exists.
The input_output_pair_t derived type encapsulates training-data pairings ensuring a one-to-one connection between tensor_t inputs and outputs as required for supervised learning [Goodfellow et al., 2016]. The mini_batch_t type supports the formation of input_output_pair_t subgroups. The ability to form mini-batches and to randomly shuffle the composition of mini-batches via the listed shuffle subroutine combine to facilitate the implementation of the foundational stochastic gradient descent optimization algorithm for training.
Finally, the training_configuration_t and training_data_files_t types encapsulate file formats that Fiats users employ to define training hyperparameters (e.g., learning rate) and to specify the collection of files that contain training data. With all of the aforementioned derived types in place, train-cloud-microphysics uses a capability of the external Julienne framework [Laba] to group the training data into bins:
bins = [(bin_t(num_items=num_pairs, num_bins=n_bins, bin_number=b), b = 1, n_bins)]
and then these bins are shuffled into new mini-batch subsets at the beginning of each epoch:
do epoch = first_epoch, last_epoch
if (size(bins)>1) call shuffle(input_output_pairs) ! set up for stochastic gradient descent
mini_batches = [(mini_batch_t(input_output_pairs(bins(b)%first():bins(b)%last())), b = 1, size(bins))]
call trainable_network%train(mini_batches, cost, adam, learning_rate)
where cost is an intent(out) variable containing the cost function calculated at the end of an epoch; adam
is a logical intent(in) variable that switches on the Adam optimizer [Kingma and Ba, 2017]; and learning_rate is an intent(in) variable that scales the adjustments to the model weights and biases. This completes the presentation of essential Fiats capabilities employed by train-cloud-microphysics.
Discussion
This section aims to provide the interested reader with experience in running programs that use Fiats for predicting atmospheric aerosol dynamics and for training a cloud microphysics model.
Build system and compiler installation
Building Fiats requires the Fortran Package Manager (fpm) and the LLVM flang Fortran compiler. The “package manager” part of fpm’s name refers to fpm’s ability to download, if necessary, and build a project’s dependencies if those dependencies are also fpm projects. Because LLVM is not an fpm project, fpm cannot build flang.
The commands in this notebook were tested with fpm 0.11.0 and flang 20.1.2. It might be easiest to install fpm and flang using package managers – for example, using the Homebrew command brew install fpm flang on macOS or the command sudo apt install fortran-fpm flang-20 on Ubuntu Linux. Also, the spack multi-platform package manager installs flang on Windows, Linux, and macOS. For example, the following three instructions from the current spack README.md file suffice to install flang in a bash, zsh, or sh shell:
git clone -c feature.manyFiles=true --depth=2 https://github.com/spack/spack.git
. spack/share/spack/setup-env.sh
spack install llvm+flang
where only the second of these three steps changes for other shells. The spack README.md provides alternatives for the tcsch and fish shells.
Alternatively, if you have the GNU Compiler Collection (GCC) gfortran compiler, an especially easy way to install fpm is to compile the single file that each fpm release offers with all of fpm’s source code (which is written in Fortran) concatenated into one file. On the fpm 0.11.0 release page, for example, that file is fpm-0.11.0.F90. Downloading that file to an otherwise empty directory (because compiling it produces many files, all but one of which can be deleted after compiling), compiling with a command such as gfortran -o fpm -fopenmp fpm-0.11.0.F90, and moving the resulting fpm executable file to a directory in your PATH gives you a working installation of fpm. In the provided single-file compile command, -fopenmp enables fpm to shorten compile times via parallel builds.
With fpm and flang installed and the repository cloned as explained in the Getting started section of this notebook, and with your present working directory set to anywhere in the clone, you can build and test Fiats with the command:
fpm test --compiler flang-new --flag -O3
where we invoke flang via the alias flang-new for historical reasons. We expect that an upcoming version of fpm will recognize flang as LLVM flang. If everything succeeds, the trailing output from the latter command should be:
_________ In total, 37 of 37 tests pass. _________
at which point it will be possible to run any of the programs in the Fiats example/ subdirectory.
Running microphysics training
As explained in the Objectives section of this notebook, this section uses a proxy for the much more involved train-cloud-microphysics demonstration application. The proxy is the example/learn-saturated-mixing-ratio program. The proxy trains a neural-network surrogate to represent the function defined in example/supporting-modules/saturated-mixing-ratio.f90. The function result is the saturated mixing ratio, a thermodynamic variable corresponding to the maximum amount of water vapor that the air at a given location can hold in the gaseous state without condensing to liquid. The function has two arguments: temperature and pressure. The function was extracted from ICAR’s SB04 simple microphysics model, refactored to accept arguments mapped to the unit interval [0,1], and then wrapped by a function that accepts and returns tensor_t objects from which the Fiats infer function extracts model inputs and the corresponding outputs. The resulting trained neural network stores the physics-based (SB04) model input and output extrema for purposes of capturing the mapping function that transforms data between the application data range and the model data range ([0,1]).
The learn-saturated-mixing-ratio example program uses Fiats entities that form a subset of those used by train-cloud-microphysics:
use fiats_m, only : trainable_network_t, mini_batch_t, tensor_t, input_output_pair_t, shuffle
which demonstrates why the example is a simpler proxy for the demonstration application. Because the Methods section of this notebook details the demonstration application’s use of Fiats, the current section skips over example program details and instead focuses on running the example.
When compiled and run without command-line arguments, each program in the Fiats example/ and demo/app/ subdirectories prints helpful usage information. Hence, running the provided programs without arguments is one way to find out the required arguments:
fpm run \
--example learn-saturated-mixing-ratio \
--compiler flang-new \
--flag -O3
which generates the trailing output:
Fortran ERROR STOP:
Usage:
fpm run \
--example learn-saturated-mixing-ratio \
--compiler flang-new \
--flag "-O3" \
-- --output-file "<file-name>"
<ERROR> Execution for object " learn-saturated-mixing-ratio " returned exit code 1
<ERROR> *cmd_run*:stopping due to failed executions
STOP 1
where fpm commands place command-line arguments for the running program after double-dashes (--), so the above message indicates that the program requires command-line arguments of the form --output-file "<file-name>".
The following command runs the program again with the required argument:
fpm run \
--compiler flang-new \
--flag -O3 \
--example learn-saturated-mixing-ratio \
-- --output-file saturated-mixing-ratio.json
which should produce leading output like the following:
Initializing a new network
Epoch | Cost Function| System_Clock | Nodes per Layer
1000 0.77687E-04 6.0089 2,4,72,2,1
2000 0.60092E-04 12.062 2,4,72,2,1
3000 0.45148E-04 18.110 2,4,72,2,1
4000 0.33944E-04 24.253 2,4,72,2,1
showing the cost function decreasing with increasing numbers of epochs for a neural network that accepts 2 inputs (normalized pressure and temperature) and uses three hidden layers of width 4, 72, and 2 to produce 1 output (saturated mixing ratio).
The program uses a cost-function tolerance of 1.0E-08, which takes a very long time to attain when compiled with LLVM flang 20. (An earlier version of Fiats, 0.14.0, supports compiling with gfortran, which produces executable programs that run approximately 20x faster. We anticipate supporting gfortran again in a future release after bugs in gfortran’s support for kind type parameters have been fixed. We also anticipate that future releases of LLVM flang, one of the newest Fortran compilers, will improve in the ability to optimize code and generate faster programs.)
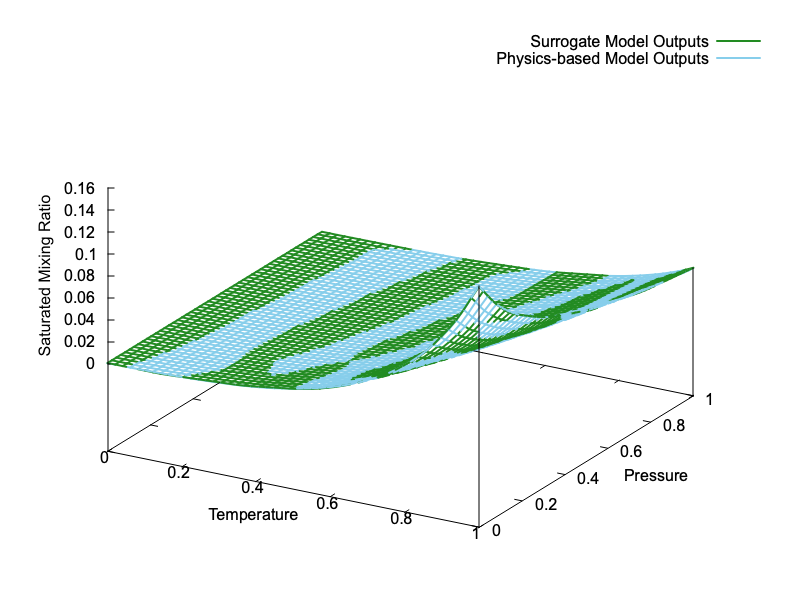
To gracefully shut down the example program, issue the command touch stop, which creates an empty file named stop. The program periodically checks for this file, halts execution if the file exists, and prints a table of model inputs along with the actual and desired model outputs. Fig. 1 compares the surrogate and physics-based model output surfaces over the unit square domain \([0,1]^2\). It demonstrates that the two surfaces are visually indistinguishable, except that whichever of the two surface colors shows at a given point indicates which surface would be visible from the given viewing angle. Viewed from above, for example, the color corresponding to whichever surface is slightly higher than the other shows. From below, whichever is slightly lower shows.
Running aerosol inference
This section of the notebook uses the concurrent-inferences program in the example/ subdirectory as a proxy for the more involved infer-aerosol demonstration application in the demo/app subdirectory. This example program performs batches of inferences taking a three-dimensional (3D) array of tensor_t input objects and producing a 3D array of tensor_t output objects. The sizes of the 3D arrays is representative of the grids used in an ICAR production run.
Run the proxy with no command-line arguments for the program itself:
fpm run --example concurrent-inferences --compiler flang-new --flag -O3
which should yield the usage information:
Usage:
fpm run \
--example concurrent-inferences \
--compiler flang-new --flag -O3 \
-- --network "<file-name>" \
[--do-concurrent] [--openmp] [--elemental] [--double-precision] [--trials <integer>]
where <> indicates user input and [] indicates an optional argument.
where the first three optional arguments specify a strategy for iterating across the batch: Fortran’s loop-parallel do concurrent construct, OpenMP multithreading, or an elemental procedure that operates on whole tensor_t arrays or array slices in one infer invocation. If none of the first three optional arguments exists on the command line, then all three execute. The fourth optional argument decides whether to additionally perform inference using double precision. The final optional argument determines the number of times each strategy will execute. See [Rouson et al., 2025] for a discussion of the performance of each of these approaches.
Before running concurrent-inferences, download the pretrained aerosol model file model.json and save it to the root directory of your Fiats clone.
To import the pretrained model and run the program, enter the following command:
fpm run \
--example concurrent-inferences \
--compiler flang-new --flag -O3 \
-- --network model.json
which should yield trailing output of the form:
Constructing a new neural_network_t object from the file model.json
Defining an array of tensor_t input objects with random normalized components
Performing 1250565 inferences inside `do concurrent`.
Elapsed system clock during `do concurrent` inference: 42.464405
Performing 1250565 inferences inside `omp parallel do`.
Elapsed system clock during `OpenMP` inference: 43.313417
Performing elemental inferences inside `omp workshare`
Elapsed system clock during `elemental` inference: 41.631988
Constructing a new neural_network_t object from the file model.json
Defining an array of tensor_t input objects with random normalized components
Performing double-precision inference inside `do concurrent`
Elapsed system clock during double precision concurrent inference: 66.173744
variable mean stdev
t_dc 42.464405 0.
t_omp 43.313417 0.
t_elem 41.631988 0.
t_dp_dc 66.173744 0.
In interpreting these timings, note that Homebrew installs LLVM flang without OpenMP support and flang’s capability for automatically parallelizing of do concurrent did not make it into flang version 20, but should appear in flang version 21. Lastly, compilers do not yet parallelize array statements inside OpenMP’s !$omp workshare blocks. [Rouson et al., 2025] present results with OpenMP support and with automatic parallelization of do concurrent enabled.
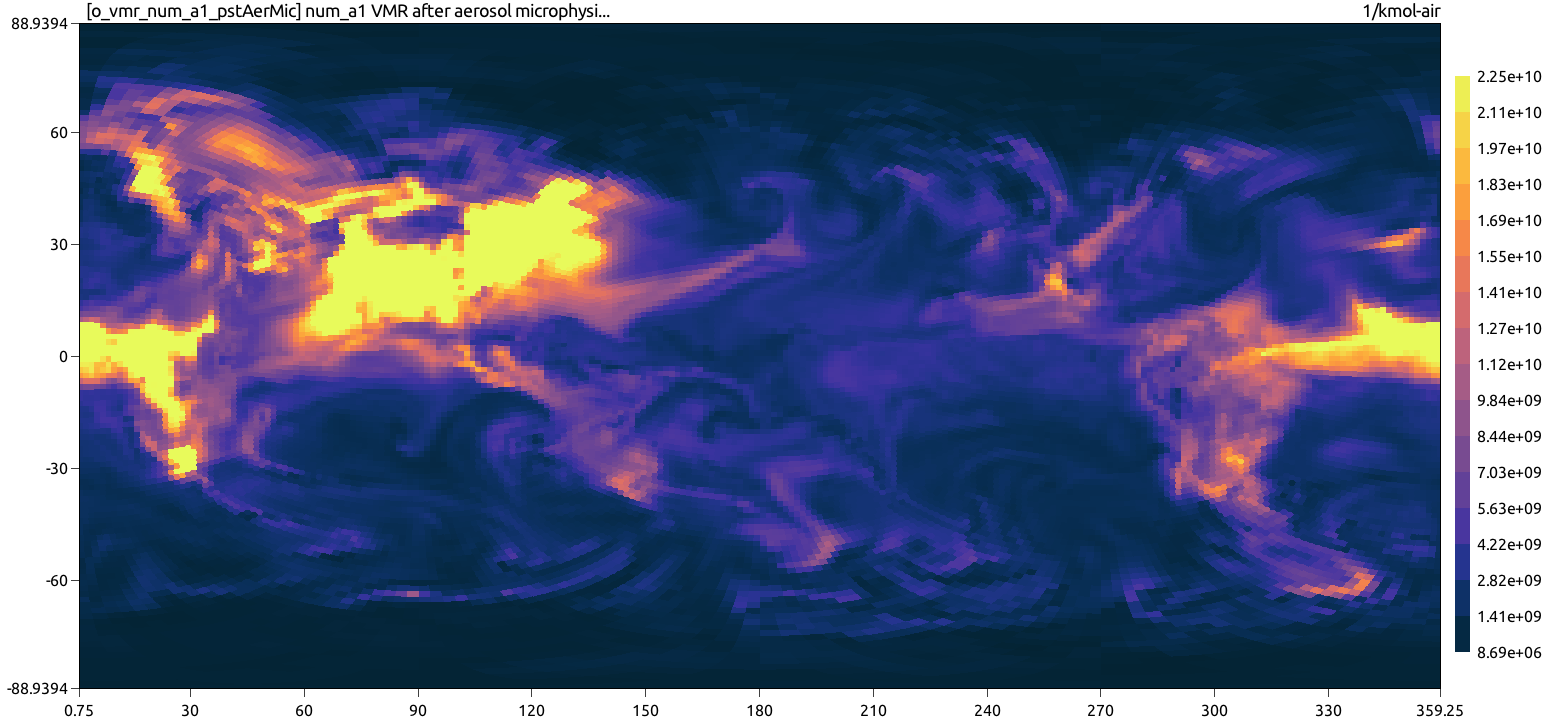
Fig. 2 visualizes predictions of the accumulation-mode aerosol concentration made by the aerosol model that we used with the infer-aerosol demonstration application. The visualization is produced by software unrelated to Fiats and is provided for purposes of understanding the model data the model produces.
Conclusions
This notebook introduces the reader to program statements that demonstration applications can use to access Fiats functionality for training a cloud microphysics surrogate model, or to perform batch inference using an aerosol surrogate. After providing information on installing the requisite compiler (LLVM flang) and build system (fpm), the notebook walks the reader through the process of running simplified example proxy programs modeled after the demonstration applications. Related visualizations demonstrate the accuracy of the microphysics model trained by Fiats and the richness of the structures representable with the pretrained aerosol model.
Acknowledgments
This material was based upon work supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research CASS (S4PST) and SciDAC (NUCLEI) programs under Contract No. DE-AC02-05CH11231.
References
- ACJP15
Michael J Asher, Barry FW Croke, Anthony J Jakeman, and Luk JM Peeters. A review of surrogate models and their application to groundwater modeling. Water Resources Research, 51(8):5957–5973, 2015. doi:10.1002/2015WR016967.
- BWH+24
Zhe Bai, Hui Wan, Taufiq Hassan, Kai Zhang, and Ann Almgren. Deep learning based aerosol microphysics surrogate model for E3SM. AGU24, 2024.
- Cur19
Milan Curcic. A parallel Fortran framework for neural networks and deep learning. In ACM SIGPLAN Fortran Forum, volume 38(1), 4–21. ACM New York, NY, USA, 2019. doi:10.1145/3323057.3323059.
- GCVR+19
Jean-Christophe Golaz, Peter M Caldwell, Luke P Van Roekel, Mark R Petersen, Qi Tang, Jonathan D Wolfe, Guta Abeshu, Valentine Anantharaj, Xylar S Asay-Davis, David C Bader, and others. The DOE E3SM coupled model version 1: overview and evaluation at standard resolution. Journal of Advances in Modeling Earth Systems, 11(7):2089–2129, 2019. doi:10.1029/2018MS001603.
- GBCB16
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. Deep learning. Volume 1. MIT press Cambridge, 2016. doi:10.1007/s10710-017-9314-z.
- GBC+16
Ethan Gutmann, Idar Barstad, Martyn Clark, Jeffrey Arnold, and Roy Rasmussen. The intermediate complexity atmospheric research model (ICAR). Journal of Hydrometeorology, 17(3):957–973, 2016. doi:10.1175/JHM-D-15-0155.1.
- KB17
Diederik P. Kingma and Jimmy Ba. Adam: a method for stochastic optimization. 2017. arXiv:1412.6980, doi:10.48550/arXiv.1412.6980.
- Laba
Lawrence Berkeley National Laboratory. Julienne. https://go.lbl.gov/julienne.
- Labb
Lawrence Berkeley National Laboratory. Fiats: Functional inference and training for surrogates. https://go.lbl.gov/fiats.
- MHW15
George Mozdzynski, Mats Hamrud, and Nils Wedi. A partitioned global address space implementation of the european centre for medium range weather forecasts integrated forecasting system. The International Journal of High Performance Computing Applications, 29(3):261–273, 2015. doi:10.1177/1094342015576773.
- PER+22
Sam Partee, Matthew Ellis, Alessandro Rigazzi, Andrew E Shao, Scott Bachman, Gustavo Marques, and Benjamin Robbins. Using machine learning at scale in numerical simulations with SmartSim: an application to ocean climate modeling. Journal of Computational Science, 62:101707, 2022. doi:10.1016/j.jocs.2022.101707.
- RBB+25(1,2,3,4,5)
Damian Rouson, Zhe Bai, Dan Bonachea, Ethan Gutmann, Katherine Rasmussen, Brad Richardson, Sameer Shende, David Torres, Yunhao Zhang, Kareem Ergawy, and Michael Klemm. Automatically parallelizing batch inference on deep neural networks using Fiats and Fortran 2023 "do concurrent". In Fifth Workshop on Computational Aspects on Computational Aspects of Deep Learning, Lecture Notes in Computer Science. 2025. doi:10.25344/S4VG6T.
- SKB+24
Mingjie Shi, Michael Keller, Barbara Bomfim, Lingcheng Li, Charlie Koven, Lara Kueppers, Ryan Knox, Jessica Needham, Shih-Chieh Kao, Peter E Thornton, and others. Functionally assembled terrestrial ecosystem simulator (FATES) for hurricane disturbance and recovery. Journal of Advances in Modeling Earth Systems, 16(1):e2023MS003679, 2024. doi:10.1029/2023MS003679.
- SKD+08
William C Skamarock, Joseph B Klemp, Jimy Dudhia, David O Gill, Dale M Barker, Michael G Duda, Xiang-Yu Huang, Wei Wang, Jordan G Powers, and others. A description of the advanced research WRF version 3. NCAR technical note, 475(125):10–5065, 2008. doi:10.5065/D68S4MVH.
- Tay24
Ned Thaddeus Taylor. ATHENA: a Fortran package for neural networks. Journal of Open Source Software, 9(99):6492, 2024. doi:10.21105/joss.06492.
- VMM+21
Marcos Vanella, Kevin McGrattan, Randall McDermott, Glenn Forney, William Mell, Emanuele Gissi, and Paolo Fiorucci. A multi-fidelity framework for wildland fire behavior simulations over complex terrain. Atmosphere, 12(2):273, 2021. doi:10.3390/atmos12020273.